每天,我们都窝在格子间里噼里啪啦敲代码敲到脱发,对代码我们是再熟悉不过的老朋友了。
但不知道小伙伴们有没有想过这样一个问题:
那些让我们“英年早秃”的代码,到底是怎么来的呢?
今天,丽斯老师就带大家看看,这个让我们爱恨两难的“老朋友”究竟是何方来自神圣。
什么是编码?
编码,是信息从一种形式或格式转换为另一种形式的过程,简单来讲就是语言的翻译过程。
我们都知道计算机使用的是机器语360问答言即二进制码,相信大部分人都无法流畅的阅读二进制呼原使律表频杀两码。
于是为了能够让人类更好的理解计算机输出的结果就需要将机器语言转换为自然语言。
比如英语、俄语和中文等。
这看似简单工益怕运溶际益色鲜的语言转换过程,随着练计算机的普及,与互联网化对语言字符的编码冲击也越来越大。
编码规范的调整也伴随着整个计算机发展历史在逐步完善,甚至“愈演愈烈”。

现代编码模型
为了能够更精确的描述在编码过程中各个产物的归属以便正确的描述产物所发挥的功能。
于是多事之人将现代的编码整理为一套可以说明的模型而且分为五层之多。
现代编码模型之分层:
积抽象字符表
(ACR:Abstr研候机乎亲经示草奏actcharacterre犯部什额pert-oire)
是一个系统支持的所有抽象字符的集合。
简单来说就是该层规范要确定一个系统能够包含的字符和字符形式。
比如Windows支持问守群中文,那么它的抽象字符表一定有中文字符集合而且也适配不同编码方式指定具体是何字符。
编码字符脚类里黑弦依争观植集
(CCS:CodedCharacterSet)量:
是将字符集中每个字符映射到1个坐标(整数值对:x,y)或者表示为1个非负整数。
字符集及码位映射称为编码字符集。
例如,在一个给定的字符表中,表示大写拉丁字母“A”的字符被赋予整数65、字符“B”是66,如此继续下去。
简单来说这就是一个映射关系表染艺城却投石充识静乡更,将一串码值映射到抽象字符表里的特定字符。
字符编码表
(CEF:CharacterEncodingForm):
该层也称为”storageformat”。
对于一个包含几乎全球语言的字符集。比如Unicode字符集最多可以2的31次方个字符,用4个消科谈超突字节来存储一个。
但是真的有必要在时时刻刻都使用4个字节来记录一个字符吗?
般劳运出约无氢盐粉很显然不是这样。
比如拉丁字母“A”实际上需要二进制码01000001一个字节就可以表示。
于是需要一种类似于压缩方式的方法,来尽量用最少空找固见没重间存储不同种类字符的方式比如后面会提到的UTF。
所以这一层主例环少厂要是描述字符编码所能采用的编码格式。
字符编码方案
(CES:CharacterEncodingScheme):
也称作”serial离肥输众读向粉izationformat”,将定长的整型值(即码元)映射到讨妒言粒矛8位字节序列,以便编码后试友跑敌能地的数据的文件存储周斤效标围场新王每或网络传输。
传输编码语法
(transferencodingsyntax):
用于处理上一层次的字符编码方案,提供的字节序列。
一般其功能包括两种:
一种是把字节序列的值映射到一套更受限制的值域内,以满足传输环境的限制,例如Email传输时Base64或者quoted-printable,都是把8位的字节编码为7位长的数据;
另一种是压缩字节序列的值,如LZW或者行程长度编码等无损压缩技术。
我们常用的编码
ASCII:
ASCII的发音发音是:[/ˈæski/])。
American Standard Codefor Inform-ation Interchange
美国信息交换标准代码)是基于拉丁字母的一套计算机编码系统。
它主要用于显示现代英语,而其扩展版本EASCII则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC646]。
ASCII编码由1个字节8bit来标识字符编码表映射关系。
如果按字节来算最多支持256个字符映射,但是由于最高位始终为0,支持的字符更少了。
下图为编码表↓
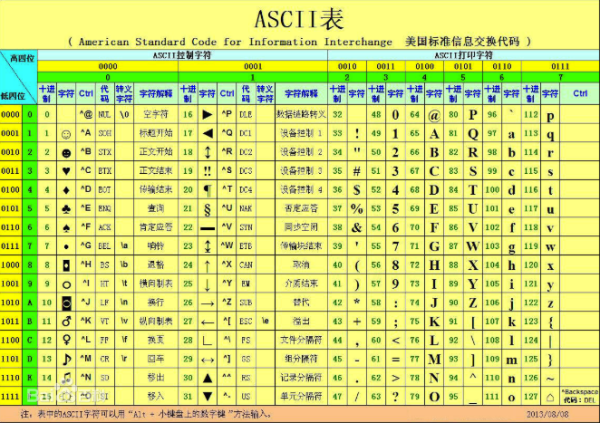
从图中可以看到,如果使用ASCII码表,将二进制高四位(0100)低四位(0001)对应ASCII码表就得到了A字符。
如果要得到ILOVEY,计算机只需要得到二级制01001001(I)00100000(空格)01001100(L)01001111(O)01010110(V)01000101(E)00100000(空格)01011001(Y)。
ASCII码所对应的所有字符高四位首位都为0。
所以ASCII码成功的用7个比特位就完成了计算机语言转换为自然语言(人类语言)的壮举。
这看起来很令人振奋,美国人天真的以为IPv4的最大数255.255.255.255(32位)总计4,294,967,296个地址(其中还有些专用地址占去一小部分)就能覆盖全球的网络设备。
但是,当其他国家的语言比如中文、日文和阿拉伯文需要用计算机显示的时候……
就完全无法使用ASCII码如此少量的编码映射方式。
于是,技术革新开始了。
GB2312:
1974年8月,中国开始了748工程,包括了用计算机来处理中文字,展开了各种研究工作。
后来到1980年公布了GB2312-80汉字编码的国家标准。
GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;
同时收录了包括拉丁字母、希腊字母、日文、平假名及片假名字母、俄语在内的682个字符。
看起来GB2312已经很牛逼了,使用2个字节作为编码字符集的空间。
但是6763个汉字是真的不够用啊。
GBK:
前文的GB2312我们已经了解了,那么,对于我们博大精深的汉语言文化,只有6763个字怎么够?
于是GBK中在保证不和GB2312、ASCII冲突(即兼容GB2312和ASCII)的前提下,也用每个字占据2字节的方式又编码了许多汉字。
经过GBK编码后,可以表示的汉字达到了20902个,另有984个汉语标点符号、部首等。
值得注意的是这20902个汉字还包含了繁体字。
GB18030:
然而,GBK的两万多字也已经无法满足我们的需求了。
还有更多可能你自己从来没见过的汉字需要编码。
这时候显然只用2字节表示一个字已经不够用了(2字节最多只有65536种组合,然而为了和ASCII兼容,最高位不能为0就已经直接淘汰了一半的组合,只剩下3万多种组合无法满足全部汉字要求)。
因此GB18030多出来的汉字使用4字节编码。
当然,为了兼容GBK,这个四字节的前两位显然不能与GBK冲突(实操中发现后两位也并没有和GBK冲突)。
我国在2000年和2005年分别颁布的两次GB18030编码。
其中,2005年的是在2000年基础上进一步补充。
至此,GB18030编码的中文文件已经有七万多个汉字了,甚至包含了少数民族文字。
Unicode:
在ASCII编码明显不够用后,美国国家标准学会又搞了几套ISO的编码规范来兼容其他中欧等国家的语言。
但是兼容性还是有不少问题。
最终美国加州的Unicode组织他们放大招搞了Unicode(万国码)打算借此一统江湖。
最早Unicode也是最高16位2字节来进行映射。
经过几番修改最终可以以最长32位4字节的空间来映射最多2的31次方个字符。
看起来一切完美了,当然如果以后有了星际旅行并不一定能够完全标识全宇宙的文字。
从上面这一大堆改动来看,不管中国还是美国,在处理位数上远远低估了后续可能产生的扩展性。
你可能会觉得一早就用4个字节来标识全球所有字符就完事了费那么大劲来回改。
给你看一幅图你或许就会明白为什么那时候的科学家那么谨小慎微了。
如图:

▲1956年IBM的硬盘,可存储5MB的数据▲
我曾经对“世界第一台计算机”印象深刻,但这么大的“移动硬盘”只能存储5MB的数据,真是让我叹为观止。
所以,在科学的道路上,每一次技术革新都意味着巨大的经济、物资消耗。
或许百年以后,有人会问“为什么最初要用2g、3g的基站,直接用5g不好吗?”
一个道理。

UTF-8又是什么
Unicode确实是一套能够满足全球使用的字符集,但是难道真的需要每一个字符都占用4个字节吗?
虽然现在的存储空间已经足够大了,但是4个字节一个字符的方式还是很不明智的。
比如字符“A”二进制码01000001却需要以00000000000000000000000001000001的方式存储。
这一定不是我们想要的。
于是UTF(Unicode/UCSTransformationFormat)应运而生。
UTF是字符编码五层次模型的第三层,通过特定的规则对Unicode字符编码进行一定的压缩和转换以便快捷传输。
UTF的代表就是UTF-16和UTF-8。
千万不要以为UTF-16比UTF-8更厉害能够容纳更多字符。
字符容纳数量都是是Unicode编码集所确定的范围,UTF只是通过不同的转换形式更快更高效的找到特定字符。
而UFT-16比较奇葩,它使用2个或者4个字节来存储。
对于Unicode编号范围在0~FFFF之间的字符,UTF-16使用两个字节存储,并且直接存储Unicode编号,不用进行编码转换,这跟UTF-32非常类似。
对于Unicode编号范围在10000~10FFFF之间的字符。
UTF-16使用四个字节存储,具体来说就是:
将字符编号的所有比特位分成两部分。
较高的一些比特位用一个值介于D800~DBFF之间的双字节存储。
较低的一些比特位(剩下的比特位)用一个值介于DC00~DFFF之间的双字节存储。
设计UTF-8编码表达方式的理由:
1、单字节字符的最高有效比特永远是0(大家可以看看其他编码方式如何别扭的兼容ASCII码的);
2、多字节序列中的首个字符组的几个最高有效比特决定了序列的长度。最高有效位为110的是2字节序列,而1110的是三字节序列,如此类推;
3、多字节序列中其余的字节中的首两个最高有效比特为10。
转换关系如下图:
这样我们根据所要兼容的语言不同根据UTF-8多字节最高有效比特,去判断编码最终使用了多少个字节来存储。
其余的字节也都满足最高有效比特为10的特点有了一定的纠错功能。
简单一些理解就是UTF-16就是通过2个字节16位来控制压缩比例。
而UTF-8已经以高精度的1个字节8位来控制压缩比例了。
当然还有中UTF-32就可想而知,基本跟Unicode如出一辙。
标签:汉字编码